

Em 2020, Altitude foi adquirida por Enghouse Systems
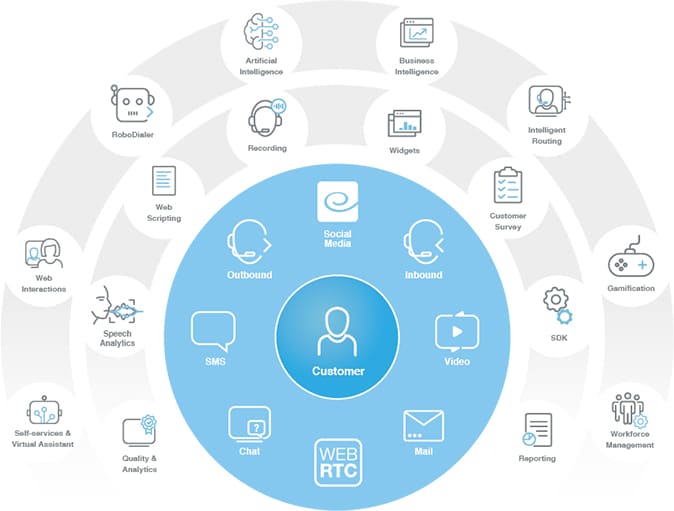
Conheça nosso portfólio
Temos o portfólio mais completo para seu Contact Center, para que você possa oferecer um serviço on-channel, implementado no local ou em Cloud.
Smart Staff Optimization (SSO)
Aproveite os benefícios e oportunidades que o trabalho remoto traz ao Contact Center com um conjunto de ferramentas que lhe permite gerenciar adequadamente as operações a distância.
- Business Intelligence
- Quality Management Suite
- Workforce Management
- Gamificação para Contact Center
- Vidyo para Contact Center
Integre facilmente o canal de vídeo interativo em seus aplicativos, com a mais alta qualidade e resolução de até 4K UHD, graças à tecnologia de vídeo mais segura, escalonável e personalizável do mercado.
Crie aplicativos com chat de vídeo multipartidário nativos, móveis e WebRTC.
API e SDK consistentes para integrar rapidamente o canal de vídeo em todas as plataformas.
Eu quero saber mais!
Cobranças
Ofereça auto-atendimento através de um assistente virtual, emulando a experiência de um agente de cobrança e seguindo as mesmas regras comerciais.
BPO
Otimize os processos de BPO implementando soluções baseadas em tecnologia que melhoram a eficiência das operações e atendem às necessidades de seus clientes.
Video Banking
Melhore a experiência do cliente oferecendo pontos de contato adicionais através do canal de vídeo, proporcionando um serviço personalizado mais rápido e eficiente em tempo real.
Cada conversa aumenta o envolvimento e a compreensão, o que reduz o tempo de cada transação.
Melhore a interação de cada cliente aumentando a lealdade, confiança e satisfação com os processos e transações financeiras.
Eu quero saber mais!